GoogleスプレッドシートでURLから記事タイトル(headタグ内のtitleタグの中身)を取得する方法を教えてもらったのですが、いろいろ状況による使い分けが必要そうなのでまとめます。

URLからタイトルを取得するシンプルな形
一番シンプルな形態です。
=importxml(“https://xxx”,”//title”)
https://の箇所にはスプレッドシートのセルを指定するのが一般的かと思います。
ただこの場合だと、headタグ意外にもページ上にtitleタグが使われているとそのタイトルまで取得してしまいます。SVGの中にtitleタグが使われていたりして大量にタイトルが出てきてしまいます。
URLから初めのタイトルを取得する
1番目にくるtitleのみを取得してくれるようになります。
=INDEX(IMPORTXML(“https://xxx”,”//title”),1,1)
他にも=text(importxml(“URL”,”//title”),””)として取得することもできます。
https://がない場合
URLの一覧データでhttps://が省略されている場合上記の書き方だと#N/Aになってしまいます。
=INDEX(IMPORTXML(CONCATENATE(“https://”,セル),”//title”),1,1)
CONCATENATE()を使ってhttps://を追加してあげています。パーマリンクしかない場合などにも使えます。
大量にURLからタイトルを取得する場合
大量データを一度に処理しようとしたところ、「読み込みエラー」が消えなくなったことがありました。待てばよかったのかもしれませんが、Chromeを再起動したりしても治る見通しが立たなくなり、とりあえず、ググってCookieを消す手順を試したけれどだめでした。シークレットウィンドウもファイルのコピーも試したがだめでapp scriptを試すことにしました。
複数Googleアカウントでログインしたりしていたので、そのせいもある気がするので上記に書いた方法でも大量データを扱えたかもしれません。
参考元:Google SpreadsheetでURLからタイトルに変換
スプレッドシートで初めて使ったのでうまく動かせなかったのでその時の補足を踏まえて書きます。
スプレッドシートから「拡張機能」→「Apps Script」を選びます。
Apps Scriptを開きコード.gsには以下のコードがデフォルトで入っていますが、トラップなので消します。
function myFunction() { }
これはいらないので消します。実行をクリックすると成功するので正しいのかなと思っていましたが、これのせいで動きませんでした。ググっても四角形の図形作らされるし遠回りしました。
実行すると権限が〜とでてくる場合は許可します。
app scriptのコード.gsに以下のコードを貼り付けます。
function URLtoTitle(url) {
var response = UrlFetchApp.fetch(url);
var myRegexp = /<title>([\s\S]*?)<\/title>/i;
var match = myRegexp.exec(response.getContentText());
var title = match[1];
title = title.replace(/(^\s+)|(\s+$)/g, “”);
return(title);
}
※ 参考元:Google SpreadsheetでURLからタイトルに変換より抜粋(より詳細は参考元へ)
保存して名前をつけておきましょう。実行する項目にURLtoTitleが選択されるようになります。
以下画像が完成形です。実行をクリックしてもエラーを吐いていますがこれは引数(url)がないよと言っているだけなので無視してOKです。
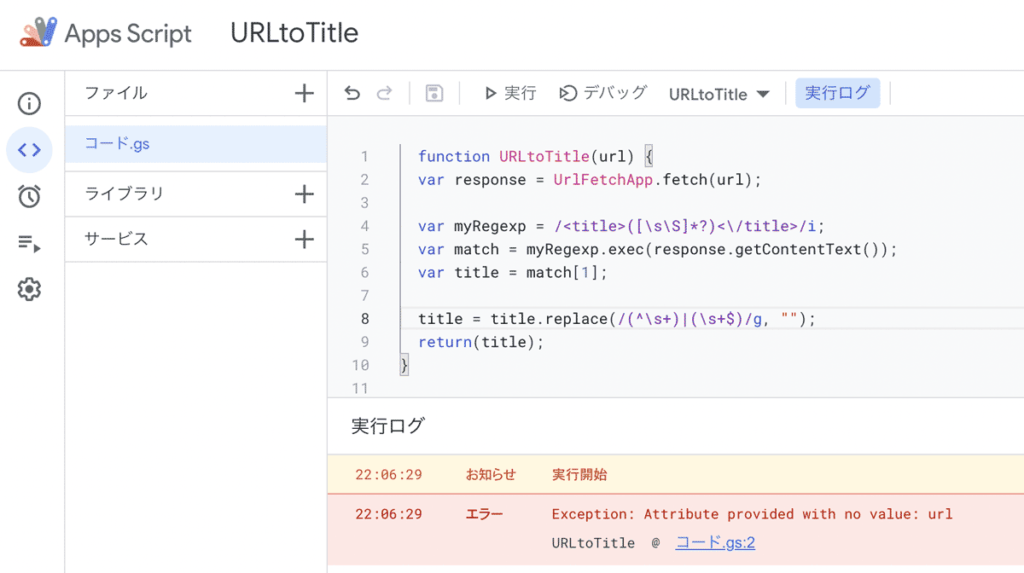
これで使えるようになります。
スプレッドシートに戻ったら一度再読み込みします。
その後 =URLtoTitle(セル) で使えるようになります。
大量のデータでも時間はかかるのですが、途中で処理が止まることもなくなんとか成功しました。
怖かったので取得したタイトルはコピーして特殊貼り付け→値のみ貼り付けで関数は消しました。(うっかり戻るを押すと再読み込みがかかったりして重かったので)
別のスプレッドシートで同じ関数を使い回す方法を探したのですが、同じ手順で作る方法しか見当たらず。解明できたら追記します。
おわり
Webスクレイピングの機能にふれてやっぱりWebスクレイピングってすごいなと思ったのと同時にデータ通信で処理が重くなってしまうのかなと勉強になりました。


