Pythonとスプレッドシートを使うようにはなったものの、一向に覚える気配がないので備忘録としてPythonにGoogleスプレッドシートのデータを読み込む方法を残します。
スプレッドシートとPythonを連携する準備
Pythonでスプレッドシートを扱うにはGCP (Google Cloud Platform)の設定が必要です。
GCPの準備は以下の記事で解説しています。
スプレッドシートへの共有設定まで終われば準備完了です。秘密キーもドライブに保存しておくとスムーズです。
Colabの準備
上記の記事でも書いてありますが、colab側のスプレッドシートを扱う準備です。
Colab画面では+codeでコードを記載するエリアを追加してコードを記述しています。(まとめて書く方法もあるかもしれませんが、わかりやすいかなと思っています)
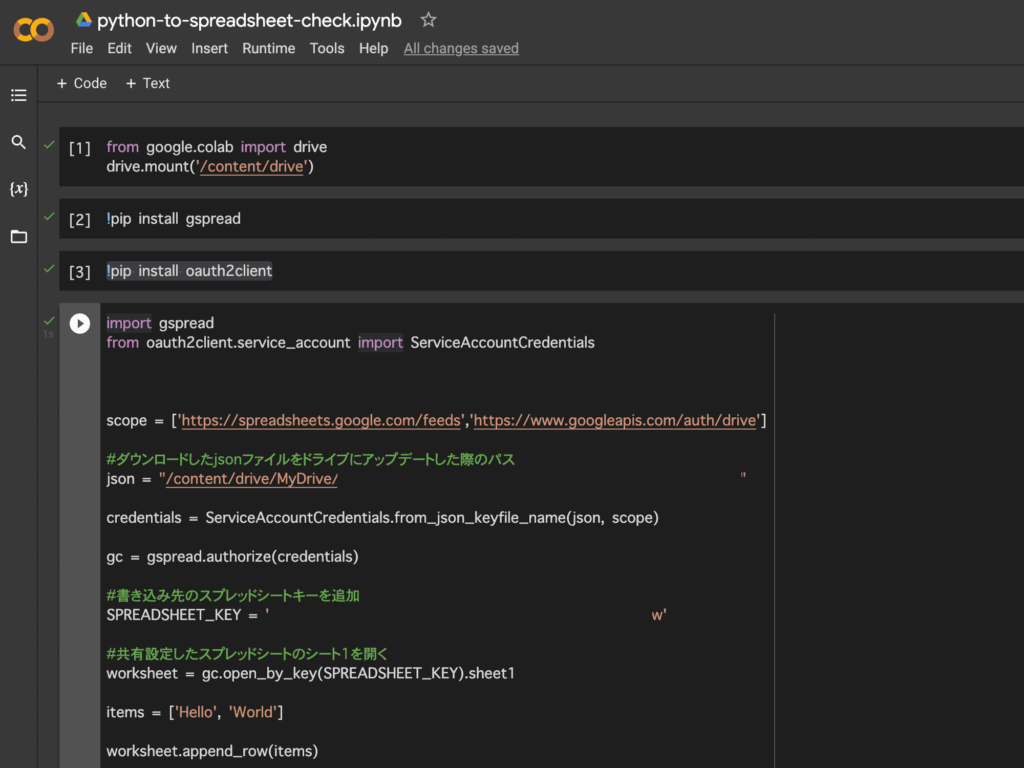
Googleドライブマウント用のコード
秘密キーのjsonデータをドライブに上げるため、マウント用のコード。
from google.colab import drive
drive.mount(‘/content/drive’)
ドライブをマウントしたら(マウントする前でも後でも良し)drive内の好きな場所へGCPで作成した秘密キーのJSONファイルをアップロードしておきます。
インターフェースインストール用
Googleスプレッドシートを操作するためのインターフェースをインストールするためのコード。
!pip install gspread
Google API認証用
Google API認証用のインターフェースをインストールするためのコード。
!pip install oauth2client
PythonにGoogleスプレッドシートのデータを読み込む方法
それではGoogle Colaboratoryを使ってスプレッドシートのデータを読み込む方法を紹介します。簡単なサンプルコードを用意したので、誰でも動かせるかと思います。
スプレッドシート側のデータ
スプレッドシートのセルには以下のデータが入っている想定です。
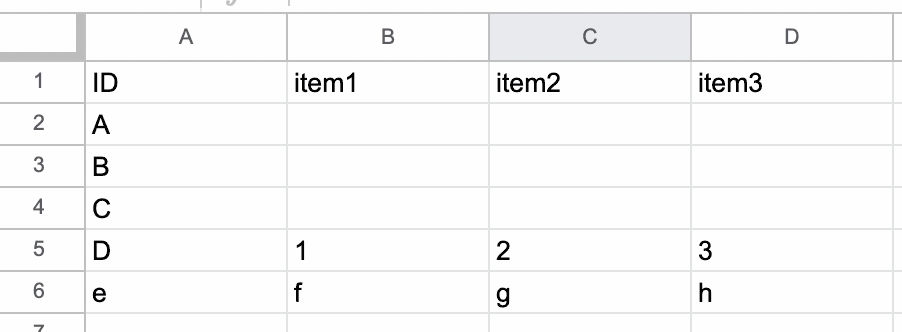
コピー用
| ID | item1 | item2 | item3 |
| A | |||
| B | |||
| C | |||
| D | 1 | 2 | 3 |
| e | f | g | h |
サンプルコード
import gspread
from oauth2client.service_account import ServiceAccountCredentials
scope = ['https://spreadsheets.google.com/feeds','https://www.googleapis.com/auth/drive']
#ダウンロードしたjsonファイルをドライブにアップデートした際のパス
json = 'ここに秘密キーのパスを貼り付け'
credentials = ServiceAccountCredentials.from_json_keyfile_name(json, scope)
gc = gspread.authorize(credentials)
#書き込み先のスプレッドシートキーを追加
SPREADSHEET_KEY = 'ここにスプレッドシートのキーを貼り付け'
#共有設定したスプレッドシートの1枚目のシートを開く
worksheet = gc.open_by_key(SPREADSHEET_KEY).sheet1
# 全てのデータを読み込む
all_data = worksheet.get_all_values()
print("全てのデータ")
print(all_data)
# 指定した縦の列の値を全て読み込む
col_data = worksheet.col_values(1) # 1行目を指定
print("縦列のデータ")
print(col_data)
# 指定した横の行の値を全て読み込む
row_data = worksheet.row_values(1) # 1行目を指定
print("行のデータ")
print(row_data)
# 指定したセルの値を読み込む
cell_data1 = worksheet.acell('A4').value # C
cell_data2 = worksheet.cell(6, 3).value # g
print("指定したセルの値")
print(cell_data1)
print(cell_data2)
# 指定した複数のセルの値を読み込む
cells_data = worksheet.get('B5:D6')
print("指定した複数のセルの値")
print(cells_data)
# 辞書型で読み込む
all_dict_data = worksheet.get_all_records()
print("辞書型の値")
print(all_dict_data)結果
全てのデータ
[[‘ID’, ‘item1’, ‘item2’, ‘item3’], [‘A’, ”, ”, ”], [‘B’, ”, ”, ”], [‘C’, ”, ”, ”], [‘D’, ‘1’, ‘2’, ‘3’], [‘e’, ‘f’, ‘g’, ‘h’]]
縦列のデータ
[‘ID’, ‘A’, ‘B’, ‘C’, ‘D’, ‘e’]
行のデータ
[‘ID’, ‘item1’, ‘item2’, ‘item3’]
指定したセルの値
C
g
指定した複数のセルの値
[[‘1’, ‘2’, ‘3’], [‘f’, ‘g’, ‘h’]]
辞書型の値
[{‘ID’: ‘A’, ‘item1’: ”, ‘item2’: ”, ‘item3’: ”}, {‘ID’: ‘B’, ‘item1’: ”, ‘item2’: ”, ‘item3’: ”}, {‘ID’: ‘C’, ‘item1’: ”, ‘item2’: ”, ‘item3’: ”}, {‘ID’: ‘D’, ‘item1’: 1, ‘item2’: 2, ‘item3’: 3}, {‘ID’: ‘e’, ‘item1’: ‘f’, ‘item2’: ‘g’, ‘item3’: ‘h’}]
サンプルコードの解説
サンプルコードを元に解説していきます。おまじないと化しているコードは省きます。
秘密キー
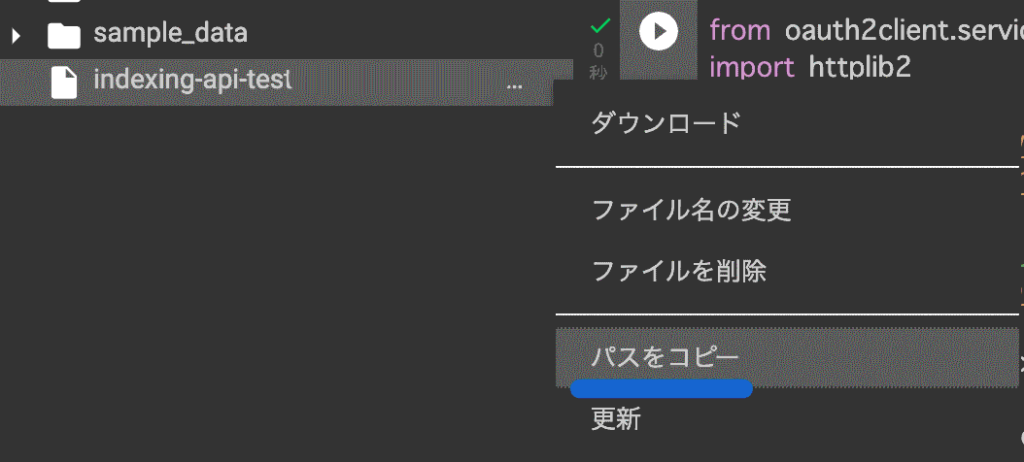
JSONデータのパスは自分の環境のものに書き変えてください。
jsonファイルのパスはcolab内の左側のファイル一覧でjsonファイルを選択し現れる「・・・」をクリックし「パスをコピー」で取得できます。
スプレッドシートのキー
スプレッドシートのキーは、スプレッドシートのURLの以下の「xxx」の部分です。環境に合わせて書き換えてください。
https://docs.google.com/spreadsheets/d/xxxxxxxxxxxxxxxxxxxxx/edit#gid=0
全てのデータを読み込む
get_all_values()では開いているシート内の全てのデータを読み込んでくれます。
all_data = worksheet.get_all_values()
いいところで自動で読み込んでくれるので便利です。
指定した縦の列の値を全て読み込む
col_values()の()内の値で列を指定しています。E列なら5と書くとE列が読まれます。
col_data = worksheet.col_values(1)
指定した横の行の値を全て読み込む
row_values()の()内の値で列を指定しています。5なら5行目が読まれます。
row_data = worksheet.row_values(1)
指定したセルの値を読み込む
acell()ではセルIDを指定します。
cell_data1 = worksheet.acell(‘A4’).value
cell()では(行番号、列番号)を指定します。C列は3になります。
cell_data2 = worksheet.cell(6, 3).value
指定した複数のセルの値を読み込む
get()では開始位置のセルIDと終了位置のセルIDを指定しその範囲のデータを取得できます。
cells_data = worksheet.get(‘B5:D6’)
辞書型で読み込む
get_all_records()では辞書型で読み込んでくれます。1行目をヘッダー(見出し、キー)として読んでくれます。
all_dict_data = worksheet.get_all_records()
おわり
gspreadは本当便利ですね。コピペに活用していただければと思います。
参考元
https://docs.gspread.org/en/latest/user-guide.html
